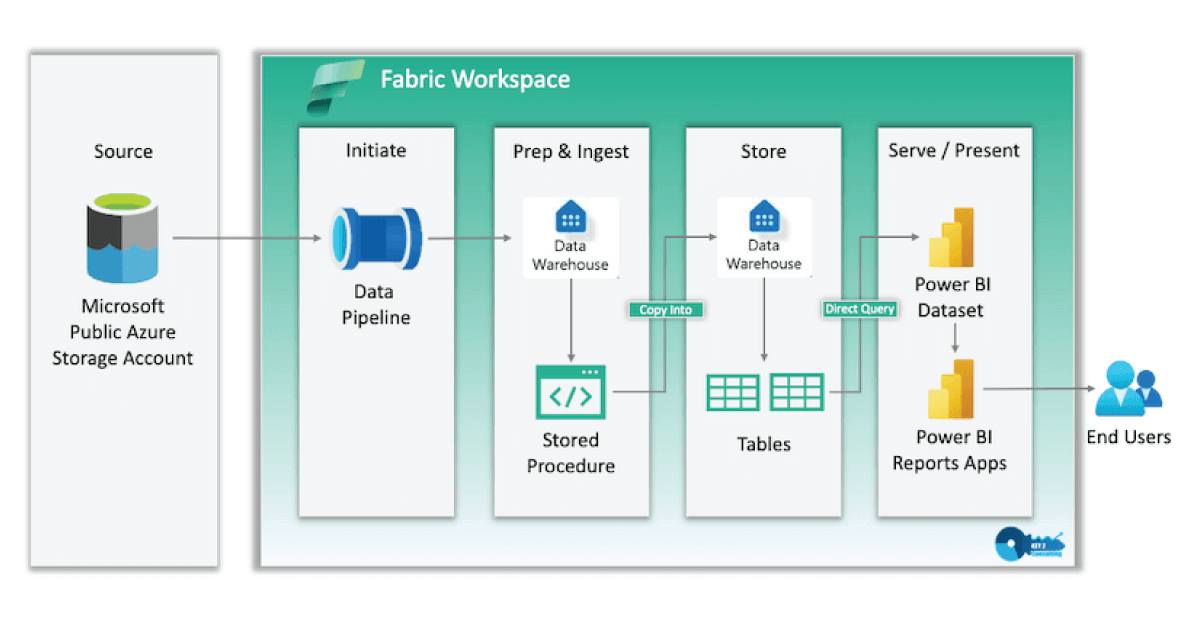
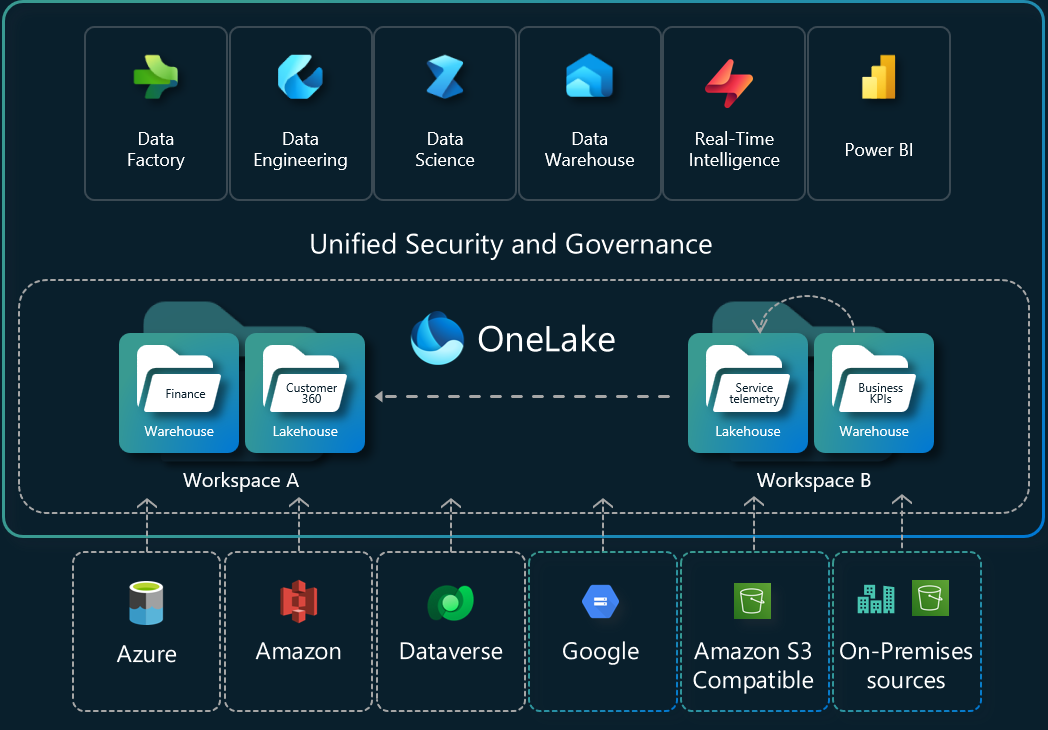
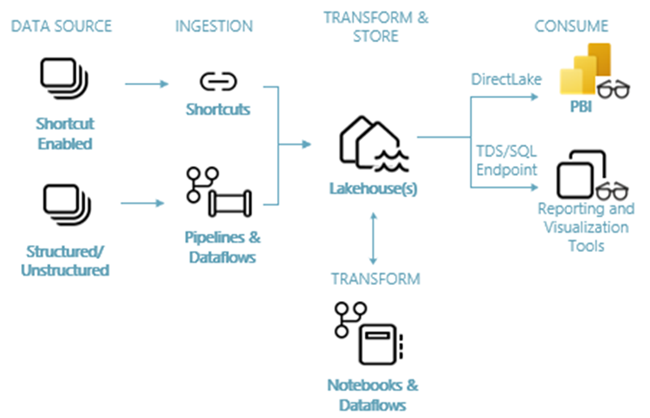
Copy job vs Copy activity Microsoft Fabric
Hello again!
Moving data remains one of the foundational activities in data engineering. Whether you’re consolidating information from multiple systems into a central lakehouse, performing regular incremental updates, or building complex ETL/ELT workflows, reliable and efficient data movement is essential for keeping analytics platforms current and accurate.
In Microsoft Fabric’s Data Factory, two powerful options stand out for handling these needs: Copy Job and Copy Data Activity. Both are designed to move data between a wide variety of sources and destinations, but they serve slightly different purposes depending on the complexity of the task.
What is a Copy Job?
Copy Job provides a streamlined, no-code (or low-code) experience for moving data without the need to build a full pipeline. It is ideal for straightforward data ingestion scenarios where you want quick setup and built-in intelligence for common patterns.
With a Copy Job, you select your source (databases, files, cloud storage, etc.), choose the destination (such as a Fabric Lakehouse or Warehouse), and configure how the data should be written. The interface guides you through connections, table selection, column mapping, and write behaviors.
Key capabilities include:
- Full copy or incremental copy modes. In incremental mode, the job automatically tracks changes using watermark columns (like timestamps or ROWVERSION) or Change Data Capture (CDC) for supported databases.
- Automatic table creation in the destination if the table doesn’t exist.
- Options to truncate the destination table before loading.
- Write methods such as Append, Upsert (merge based on keys), Overwrite, or SCD Type 2 (in preview for CDC scenarios).
- Built-in audit columns that record extraction time, job ID, and source information for better traceability.
- Scheduling support, including multiple schedules or event-based triggers.
- Performance features like auto-partitioning (in preview) for large datasets.
- Fault tolerance through resume-from-last-successful-run behavior.
Copy Jobs excel in scenarios like daily or hourly batch loads, database-to-lakehouse synchronization, or multi-source data consolidation where minimal orchestration is required.
What is Copy Data Activity?
When your requirements go beyond simple movement and involve orchestration, custom logic, or integration with other steps, the Copy Data Activity becomes the better choice. This activity is added directly to a Fabric data pipeline canvas, allowing it to sit alongside other activities such as transformations, validations, or conditional branching.
You can launch it via the Copy Assistant for a guided setup or add it manually for full control. Configuration happens across tabs for source, destination, mapping, and settings.
Key capabilities include:
- Support for custom SQL queries or stored procedures at the source.
- Advanced performance tuning: intelligent throughput optimization, degree of copy parallelism, staging for large transfers, compression, and data consistency verification.
- Fault tolerance options to skip incompatible rows.
- Parameterization for reusable activities across environments.
- Seamless integration into broader pipelines that may include Data Flows, notebooks, or other activities.
Copy Data Activity is particularly useful for complex migrations, scenarios requiring custom transformations immediately after copying, or when you need to coordinate multiple data movements with dependencies and error handling.
Comparison Table: Copy Job vs. Copy Data Activity
| Capability | Copy Job | Copy Data Activity (in Pipeline) |
|---|---|---|
| Setup Complexity | Simple, no pipeline required | Requires building and managing a pipeline |
| Flexibility | Easy-to-use with advanced options | Fully customizable and advanced |
| Native Incremental Copy | Yes (watermark-based or CDC) | No (requires custom logic or queries) |
| CDC Replication | Yes | No |
| User-defined Query | Yes | Yes |
| Table & Column Management | Yes (auto-create, truncate, mapping) | Yes (mapping, create new tables) |
| Write Behaviors | Append, Upsert, Overwrite, SCD Type 2 | Append, Upsert, Overwrite |
| Orchestration & Chaining | Limited (can be called from pipeline) | Excellent (integrates with other activities) |
| Scheduling | Yes (built-in, multiple schedules) | Yes (via pipeline triggers) |
| Performance Tuning | Automatic optimization + auto-partitioning | Detailed control (parallelism, throughput, staging) |
| Audit & Observability | Built-in audit columns | Advanced logging and pipeline monitoring |
| Best For | Routine batch/incremental loads | Complex workflows with transformations & logic |
This comparison is based on Fabric’s official decision guide for data movement.
Choosing Between Copy Job and Copy Data Activity
- Choose Copy Job when you need fast, reliable data movement with native incremental support, table management, and scheduling — but without the overhead of pipeline development. It offers a good balance of simplicity and advanced features like CDC and upsert.
- Choose Copy Data Activity when you require full customization, complex orchestration, or integration with other pipeline activities. It provides maximum flexibility at the cost of a bit more setup time.
Many teams use both approaches together: Copy Jobs for the majority of routine table syncs, and Copy Activities inside pipelines for the more intricate or transformation-heavy flows.
Both options are serverless, scale automatically, support on-premises sources via gateways, and integrate natively with the rest of Fabric (Lakehouse, Warehouse, Power BI, etc.). They also include robust monitoring so you can track run history, throughput, errors, and performance metrics.
In practice, starting with a Copy Job often gets you productive quickly. Once your needs evolve toward more sophisticated workflows, transitioning selected jobs into pipeline-based Copy Activities is straightforward.
Data movement doesn’t have to be complicated or fragile. With Copy Job and Copy Data Activity, Fabric makes it accessible, scalable, and observable — freeing data engineers to focus on higher-value work like modeling, analytics, and delivering business insights.
If you’re exploring Fabric Data Factory, I recommend trying a simple Copy Job first to experience the ease, then experimenting with the Copy Activity inside a pipeline to see the added power of orchestration.
What data movement challenges are you facing in your environment? Feel free to share in the comments.
Next in the data engineering series, we’ll explore how to combine these movement options with transformations and monitoring for robust end-to-end pipelines.
Thanks for reading! Stay tuned for more practical insights on Microsoft Fabric. Subscribe to the newsletter and keep exploring the world of data.